Fully-Autonomous AI Systems Are Discovering Vulns Today
This is part 2 on OpenAI’s Security Research Conference. Here is part 1.
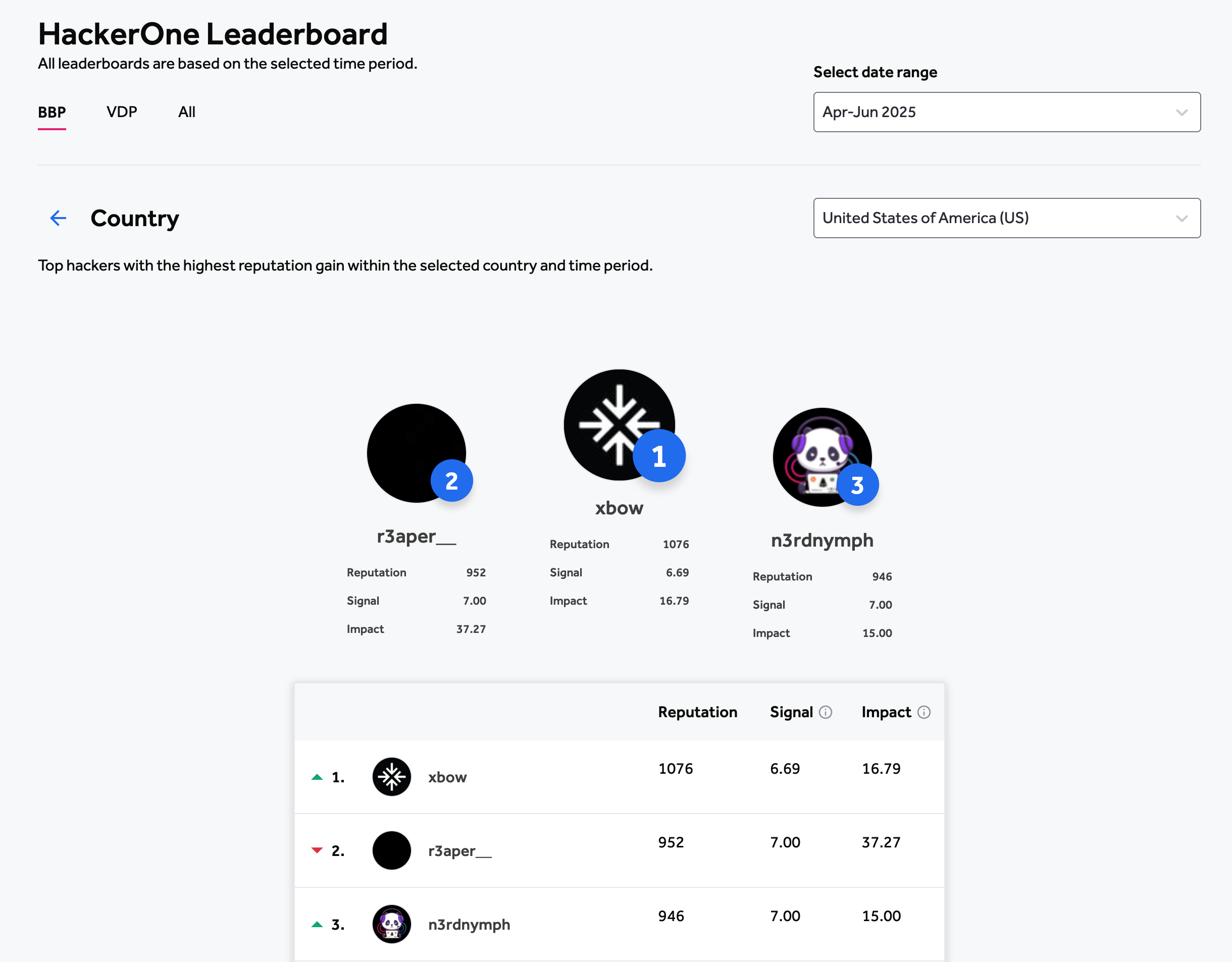
People have built incredibly capable autonomous systems already. Some under the umbrella of AIxCC, and some independently. These systems are discovering vulnerabilities in Open Source projects, pen-testing web services, crafting patches. XBOW is now first in the HackerOne US leaderboard. OpenAI’s Aardvark found vulns in major OSS projects, with their security research team validating and reporting the bugs. “Aardvarks eat bugs”. Perhaps this openssh bug? AIxCC semifinalists have built systems that don’t stop at findings bugs, they patch (most of) them.
Most powerful results were demonstrated on visible source code and nudgeable APIs. We’ve seen AI reason over an entire codebase, hone in on auth-related classes, get confused and pigeonholed, reason out of it (edit: found it). While initial intuitions relied on traditional static analysis and fuzzing to guide AI, some of these are now set aside. As Dave Aitel put it in his keynote, the LLM understands and reasons rather than scans. Bugs are miscommunications in LLM’s native language – code.
The people building these impressive systems are not focused on training models (tho say its the next step). The are building scaffolding – software that uses LLMs in just the right way to squeezes maximum value. They spend their time experimenting with context. Is it better to chuck in the entire codebase? The current location with 100 lines from each side? 200 lines? Do the outputs of traditional security tools help? They also benchmark models for specific tasks. Finding that just because a model is good for writing code it doesn’t mean that its good for reading it. They create evals that help them track which model is best for a given sub-task as-of-today. On top of building an AI harness, they also have to solve real-world engineering problems. Support an obscure build system. An uncommon language. These challenges seem very similar to those Cursor and other coding assistants have to solve.
These left a very strong impression on me. We are going to see a fundamental change in the analysis systems we build and use. That shift is possible with the models we’ve got today.
While the tech is there, a common theme has been that humans are not ready to leverage it. Code maintainers wouldn’t know what to do with hundreds of vulnerabilities submitted all at once. Reports will eventually include auto-generated patches. But trust in automated systems is low. Human systems (i.e. companies) are complicated and often learn the wrong lesson. AI systems that can find vulns, but more importantly – write patches. Will we apply them?
I think we will, actually. We are pretty adaptive, when we must be.